Amazon Redshift is one of the popular cloud-based data warehousing solution offered by Amazon Web Services (AWS). Amazon Redshift is a cluster of nodes with separate disks, memory and CPU. One of the important features of Amazon Redshift is the ability to choose from different distribution styles to manage the distribution of data and computation across nodes in a cluster. In this article, we’ll discuss the different Amazon Redshift distribution styles and the best practices for choosing the right Redshift distribution style for your needs.
Amazon Redshift Distribution Styles
There are three main distribution styles to choose from in Amazon Redshift: EVEN, KEY and ALL . You can choose any methods based on your requirement and type of joining that you are going to perform on the tables.
Apart from these three, AWS Redshift also support AUTO distribution style. When selected AUTO, Redshift will choose the best distribution style based on the table size and type of data.
- Amazon Redshift KEY Distribution
- Amazon Redshift EVEN Distribution
- Amazon Redshift ALL Distribution
- Amazon Redshift AUTO Distribution
Let us check these distribution styles in details with examples.
Amazon Redshift KEY Distribution
The Redshift KEY distribution technique uses one or more columns of the table as the distribution key. The data is divided across nodes in the cluster based on the values in the chosen columns. The leader node will place the similar rows to same data slice. If two tables are distributed on the same column, and when you join those two tables on distribution column then the required data is available in same data slice thus making collocated tables. The collocated tables improve the performance of the query.
Redshift KEY distribution Examples
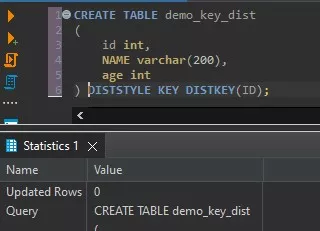
Following is the example to create a table with KEY distribution:
CREATE TABLE demo_key_dist
(
id int,
NAME varchar(200),
age int
) DISTSTYLE KEY DISTKEY(ID);Amazon Redshift EVEN Distribution
This method distributes the data evenly across all nodes in the cluster. This is the simplest distribution style and is best for small tables or those that do not have a clear distribution key. In this type of Redshift table distribution, leader node distributes the data to all data slices in a round-robin fashion
Redshift Even distribution Example
Following is the example to create table with EVEN distribution:
create table demo_even_dist
(
id int,
name varchar(200),
age int
) DISTSTYLE EVEN;Redshift ALL distribution
This method stores a complete copy of the table on every node in the cluster. This is best for small tables or those that are frequently joined with other tables. If the table is small lookup table and want make collocated tables then this distribution style is optimal.
Note that, the table loading process will take longer time if you have the Redshift table distributed on ALL style.
Related Articles,
Redshift ALL distribution Example
Following is the example to create table with ALL distribution:
create table demo_all_dist
(
id int,
name varchar(200),
age int
) DISTSTYLE ALL;Automatically Pick the Distribution Style
The latest version of Amazon Redshift can now automatically assign an optimal distribution style based on the size of the table data. With the automatic selection of the right distribution style, you get better query performance and storage space utilization across nodes.
Related Articles,
- Working with Redshift Regular Expression Functions
- How to Choose the Right Distribution Style in Redshift?
- How to Handle NULL in Redshift? – Functions
- Working with External Tables in Amazon Redshift
- How to use Redshift Primary key Constraint? Its Syntax
- Redshift WHERE Clause Multiple Columns Support
- Redshift Pivot and Unpivot Functions: A Comprehensive Guide