Amazon Redshift uses the Massively parallel processing (MPP) technique, Redshift optimally distributes data and query load across all nodes available in the cluster. In this article, we will check how to choose the Right distribution style in Redshift and the importance of right distribution key.
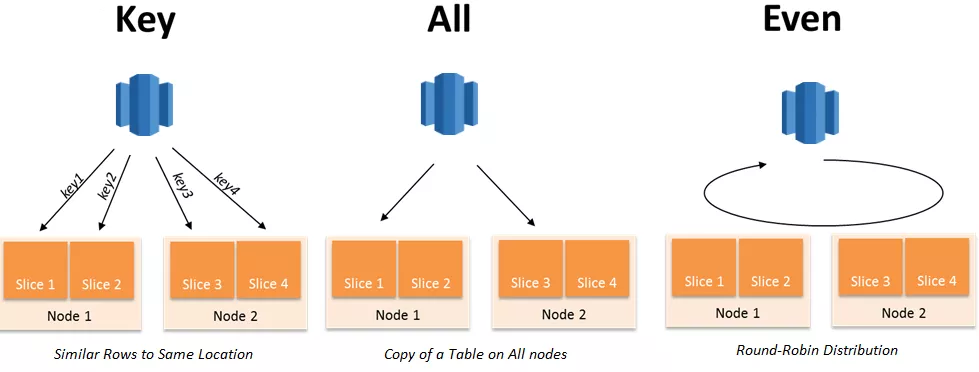
Right Distribution Style in Redshift
When choosing a distribution style, it’s important to consider the size and structure of your data and the types of queries you’ll be running.
Following are a few best practices to keep in mind while choosing an Amazon Redshift Data Distribution Strategies:
Choose a Redshift Table Distribution Key that Maximizes Query Performance
If your queries frequently filter on a specific column or set of columns, choose those columns as the distribution key. If column or set of columns used to join two or more tables, choose that column or set of columns as a distribution key. This will ensure that the data is distributed in a way that minimizes the amount of data that needs to be shuffled between nodes during complex query execution.
Consider the Size of your Data in the Redshift Table
If your table is large, choosing a distribution key that maximizes query performance may not be enough. In this case, you may need to consider additional factors such as the number of nodes in the cluster, sorting data on distribution key would enhance the performance of your joins.
Monitor your Query Performance on Redshift
It’s important to monitor query performance and adjust the distribution style as needed. This can help ensure that you’re using the right distribution style for your data and queries.
Test your complex query on a sample data set and monitor the performance with different Redshift table distribution styles.
Consider AUTO Distribution when you are not sure about Right Distribution Key
You should let Amazon Redshift decide the right distribution key for you when you are not sure about which column to use as a distribution key.
Amazon Redshift will consider the size of data in your table, number of nodes in the cluster to decide right distribution key. It will start with EVEN distribution when the table is small and changes it to KEY when size grows. It will consider ALL distribution if table is fairly small and being used as a lookup table. The ALL distribution is sometime called Amazon Redshift Replication Distribution.
Leaving out DISTKEY in Redshift distribution
By default, Amazon Redshift database data distribution uses the EVEN distribution style i.e. data is distributed using round-robin techniques.
If you are not sure about which column should be used in DISTKEY, probably AUTO or EVEN distribution style is your best choice.
What are the factors you need to Consider when Choosing a Best Redshift Distribution Style?
When choosing which columns should be the distribution style for a Redshift table, your goal should be a uniform distribution of the rows and optimal access to the data. The main goal of the distribution style is to get data co-located.
Consider the following factors when choosing best distribution style:
- Choose a column with high cardinality: The more distinct the DISTKEY values, the better.
- Parallel processing is more efficient when you have distributed table rows evenly across the slices.
- Tables used together should use the common columns for their DISTKEY.
- If a particular column is largely used in equi-join clauses, then that key is a good choice for the distribution key and sort key.
- For small tables (like date dimension), use distribution style as ALL to store copy of small table on all nodes. The table will be collocated to other tables and improves joining performance.
In conclusion, choosing the right Amazon Redshift distribution style can have a significant impact on query performance and overall cluster efficiency. By considering the size and structure of your data and the types of queries you’ll be running, you can make an informed decision about the best distribution style for your tables. Whether you choose key distribution, even distribution, all, or auto, Redshift provides the flexibility and scalability you need to manage your data and workloads effectively.
Related Articles,
- Change Redshift Table Distribution: A Guide with Examples
- How to use Redshift NOT NULL Constraint? Its Syntax
- How to use Redshift Foreign key Constraint? Its Syntax
- Set Operators in Redshift: UNION, EXCEPT/MINUS and INTERSECT
- Working with External Tables in Amazon Redshift
- Redshift Pivot and Unpivot Functions: A Comprehensive Guide