Like many other cloud data warehouses, Amazon Redshift supports set operators such as UNION, EXCEPT/MINUS and INTERSECT to combine two or more similar data sets from two or more SELECT statements. Here the similar data set literally mean, the data type of the result set should also match, otherwise you have to explicitly type cast data when using Redshift set operators.
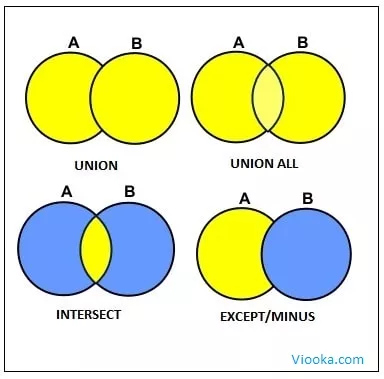
Types of Set Operators in Redshift
Amazon Redshift supports the following types of set operators:
Redshift Set Operators Syntax
Following is the syntax of Redshift set operators:
sql_query
{ UNION [ ALL ] | INTERSECT | EXCEPT | MINUS }
sql_query;
Redshift UNION and UNION ALL Set Operators
Amazon Redshift UNION and UNION ALL operation combines the results of two similar SELECT statements into a single result set that contains the rows that are returned by both SELECT statements. The data types of the participating columns should match. This operation is different from JOIN which combines columns from two tables.
A UNION operation removes duplicate rows from the result set; where as a UNION ALL expression does not remove duplicates. The UNION operation is usually costly compared to a UNION ALL hence it is recommended to use UNION ALL whenever possible.
Redshift UNION Set Operator Example
Following is the example to combine two similar results set using UNION set operator.
select * from set_test_tab1 union select * from set_test_tab2; id | name ----+------ 1 | ABC 2 | BCD 5 | DEF 6 | EFG 3 | CDE 7 | FGH (6 rows)
Redshift UNION ALL Set Operator Example
Following is the example to combine two similar results set using a UNION ALL set operator.
select * from set_test_tab1
union all
select * from set_test_tab2;
id | name
----+------
2 | BCD
5 | DEF
6 | EFG
3 | CDE
1 | ABC
3 | CDE
2 | BCD
7 | FGH
(8 rows)Redshift INTERSECT Set Operator
The Amazon Redshift INTERSECT operator combines the similar results of two or more SELECT statements into a single result set that contains rows common to both SELECT statements. The data types of the participating columns should match.
Redshift INTERSECT Operator Examples
Following is the example to combine two similar results set using a INTERSECT set operator.
select * from set_test_tab1 INTERSECT select * from set_test_tab2; id | name ----+------ 2 | BCD 3 | CDE (2 rows)
Redshift EXCEPT/MINUS Set Operator
The Amazon Redshift EXCEPT/MINUS operator finds the difference between the two or more SELECT statements and return the result contains the rows from the first SELECT statement. We can use either EXCEPT or MINUS in the statements.
Redshift EXCEPT/MINUS Set Operator Examples
Following is the example to combine two similar results set using a EXCEPT or MINUS set operator.
select * from set_test_tab1 EXCEPT select * from set_test_tab2; id | name ----+------ 1 | ABC 5 | DEF (2 rows)
Redshift Set Operator Execution Order
Following is the Redshift set operators order of execution.
- Expressions or set operators in the parentheses
- The INTERSECT operator
- EXCEPT/MINUS and UNION evaluated from left to right based on their position in the expression
Redshift Set Operator Limitations
Following are the some of limitation of set operator usage:
- If the names of the both columns in SELECT statement match, SQL displays that column name in the result. If the corresponding column names differ, SQL uses the column name from the first query in the set statement. However, you can also provide alias for columns in either of SELECT query.
- You can specify aggregate clauses such as GROUP BY and HAVING in individual sub-queries only.
- You can specify an optional ORDER BY clause only in the final query in the set statement. The ordering will apply for the result set.
- You can specify an optional LIMIT clause after the ORDER BY. LIMIT will apply to only result set.
Related Articles,
- Working with Redshift Regular Expression Functions
- How to use Redshift Foreign key Constraint? Its Syntax
- Redshift NVL and NVL2 Functions – Syntax and Examples
- Working with External Tables in Amazon Redshift
- Best Methods to Compare Two Tables in SQL
- How to Handle NULL in Redshift? – Functions
- Redshift WHERE Clause Multiple Columns Support
- How to use Redshift Primary key Constraint? Its Syntax
- How to use Redshift Unique Key Constraint? Its Syntax
Hope this helps 🙂